
![]()
Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications, whether on laptops, data center VMs, or the cloud. To know about Docker in details, click here. The installation and configuration process is described in our different blog. Click here to access that.
Here at linuxnix.com, we have a list of activities to be performed in this Docker series. With these tasks, we will be getting a clear picture of day-to-day docker use and the real-time scenarios we face where we need Docker the most. The lists of the activities are mentioned below:
- Dockerize a 2-Tier Java application by creating a Docker Image.
- Push the same Docker Image to Docker Hub.
- Run a container based version of the Application Database using the Docker-Compose file.
- Ensure data persistence by mounting the data outside of the containers.
In this section, we are going to start the fourth task. To go through the third task, click here.
Ensure data persistence in Containers via Docker
In the previous blogs, we took a Java project, created a Dockerfile. Built the image using the Dockerfile, created the container, ran it and verified the running application on the port specified. We took the same image and pushed it to the Docker Hub. We ran a database version of this application and ran both the container simultaneously via docker-compose. Now in this task, we will learn about the data persistence.
Data Persistence
Docker provides a mechanism to enable data persistence across the lifetime of the container. There are four ways to provide storage to the container.
- Docker data volumes
- Data volume containers
- Directory mounts
- Docker storage plugins
Let us learn about each one by one.
Docker data volumes
A data volume is a directory within the file system of the host machine that is used to store persistent data for containers. This directory can be usually found under /var/lib/docker/volumes. The directory will be the mount point while spinning up the container.
Data volume containers
An alternative to volume is to create a container especially used to manage data volumes. This container doesn’t run any code but acts as a single volume where other containers can access data from.
Directory mounts
This option is used to mount a directory or a file from the host machine itself to the container. This allows an existing data structure on the host to be presented to a container in a persistent and reusable format.
Docker storage plugins
It provides a mechanism to access storage on external appliances. The volume is specified on the creation of the container with the name of the volume and the mount point. There is now a range of storage plugins available in the market.
Data Persistence in Containers
In the initial phase of Docker, the intention for the container was only to be temporary in nature and spun up to manage a particular workload and then removed when the work is finished.
But now when we started running different types of containers, even databases, there is a need to save the data when it is rerun again. Now, we need persistent storage rather than the desired one.
Here in this task, we are going to use Directory mount concept for persistence. Now, we need an additional line “– ./sql:/var/lib/mysql” into mysql configuration in docker compose file. This will help to mount the directory “sql” from the host machine to the directory “mysql” in the container.
The configuration of the docker-compose.yml
The configuration of the docker-compose.yml file will look like:
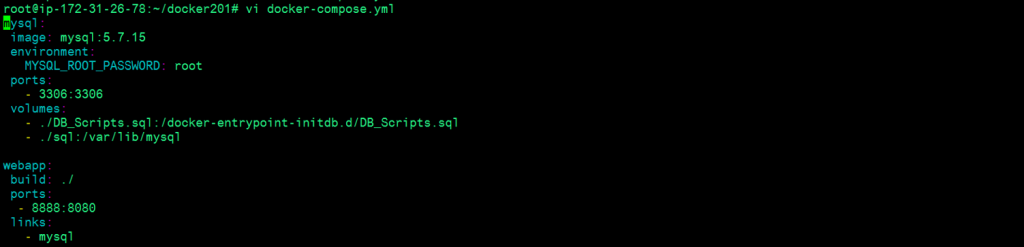
vi docker-compose.yml
mysql:
image: mysql:5.7.15
environment:
MYSQL_ROOT_PASSWORD: root
ports:
- 3306:3306
volumes:
- ./DB_Scripts.sql:/docker-entrypoint-initdb.d/DB_Scripts.sql
- ./sql:/var/lib/mysql
webapp:
build: ./
ports:
- 8888:8080
links:
- mysqlRunning both the containers
Now, we can run both of the containers using the command “docker-compose up”.
docker-compose upOnce completed, the file structure will look like:

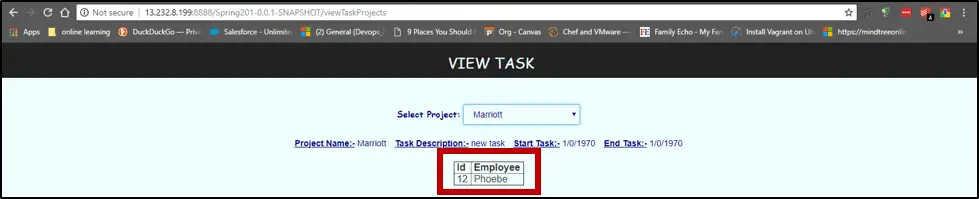
And the webpage is up and running. Now clicking on VIEW TASK. Now to verify persistence, we can check the already present data in the database. We have only one default task for Phoebe in Marriott project.
Changing the database
Now we can change the database by adding a task clicking on ASSIGN TASK. Below is the way of adding data to the database. We are adding a task for Mike in Marriott project.
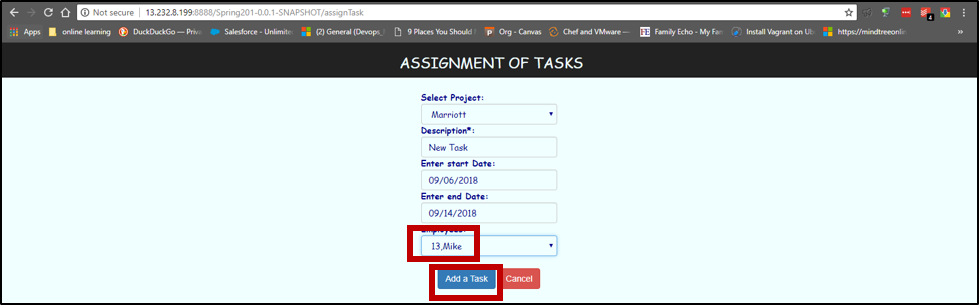
When the task is added and checked. We can see Mike is now present in the database.
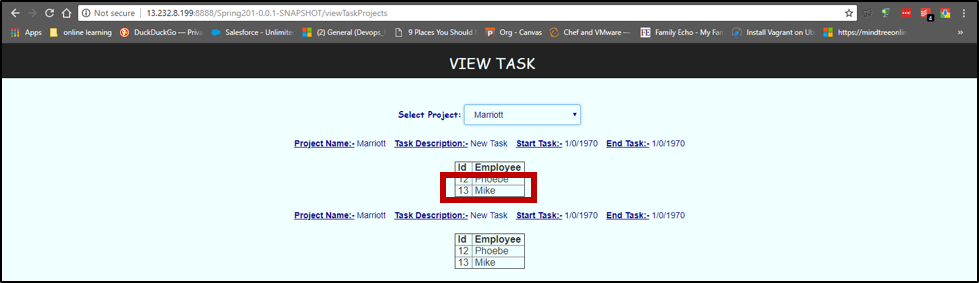
Turning down the container
Now, we will turn down the docker compose. So generally, while doing this, the container is stopped and the data will be lost. But in this case, since the data is also mounted outside the container, it will still be there.
Below is the command to turn down the Docker Compose. Now when the docker-compose is down, the webpage will also be down.
docker-compose down
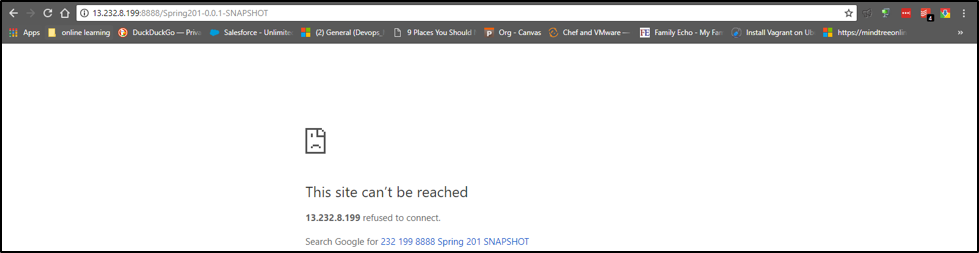
Starting the container
Let’s start the container again by using the below command and our website will be up again.
docker-compose up

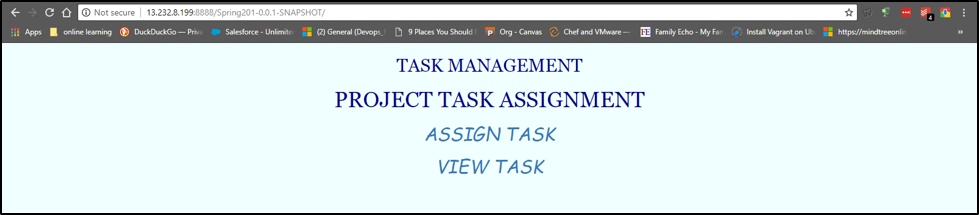
Let’s check the database created last time. We can still see Mike available in the database though we have stopped and deleted the container. This happened only because our data was mounted outside the container in our host machine.
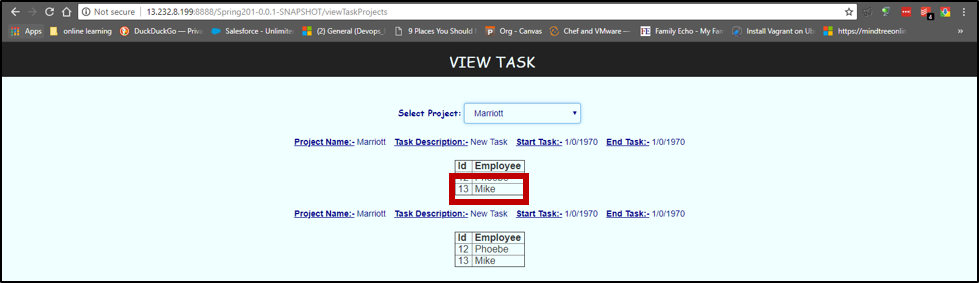
This proves that we can ensure data persistence by mounting the data outside of the containers. We have successfully finished all the tasks from this Docker session. If you have not gone through the other three, follow the below links:
- Dockerize a 2-Tier Java application by creating a Docker Image. click here
- Push the same Docker Image to Docker Hub. click here
- Run a container based version of the Application Database using the Docker-Compose file. click here
- Ensure data persistence by mounting the data outside of the containers. (Go to the top)
Stay tuned for more updates @ linuxnix.com ..
Latest posts by Ankesh K (see all)
- Deep-Dive into Jenkins – What are all Jenkins functionalities ? - January 10, 2019
- What are different Maven Plugins and how to build a Maven project? - January 7, 2019
- What is a Maven POM File and what are different Maven Repositories? - January 3, 2019
- What is Maven and what are its benefits? - December 31, 2018
- What are the different ways to install Jenkins ? - December 27, 2018


