

Introduction
In our previous article on the git version control system, we explained step by step how to create a local git repository. In this article, we will demonstrate how to add content to the empty git repository we created earlier in the previous article. We will also explain the steps that are involved in the process of saving new content to git and will also define related terminology along the way. Before we add content to our repository let us first understand the output of the ‘git status’ command where we ended our last article.
[sahil@linuxnix my_first_repo]$ git status # On branch master # # Initial commit # nothing to commit (create/copy files and use "git add" to track)
Understanding the terms commit and master:
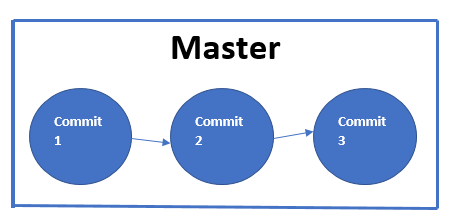
The first line of the output of the ‘git status’ command tells us that we are on the branch master and at the initial commit.
So what does this mean?
When we save a file in a git repository, git refers to this process as a ‘commit’ operation.
Here is a more detailed definition of ‘commit’ in accordance with git terminology:
A commit or revision is an individual change to a file or a set of files. In case of git creating new files within a repository would also be considered as a commit operation. A git commit is just like saving a file except with git every time we save the file it creates a unique ID (a.k.a. the “SHA” or “hash”). This unique ID allows us to keep track of what changes were made to a file and by who. Commits usually contain a commit message which is a brief description of what changes were made.
Git allows us to move from one commit state to another i.e. move from one saved state of the file to another. As we start saving these files or saving these commits, git creates a graph which is a directed acyclic graph to be specific. This graph represents the entire saved history of changes and updates made to files that were part of the repository. By default, this graph is given the name master.
Creating a README file
It’s considered a good practice to keep a README file in your git repository to make the users of that repository aware of the nature of the content that resides within the repository. I’ve created a basic README file in my repository with just one line in it.
[sahil@linuxnix my_first_repo]$ cat README.md This is a readme file for my first git repository [sahil@linuxnix my_first_repo]$
Now that we have created a file in our repository, let’s run the ‘git status’ command again.
[sahil@linuxnix my_first_repo]$ git status # On branch master # # Initial commit # # Untracked files: # (use "git add <file>..." to include in what will be committed) # # README.md nothing added to commit but untracked files present (use "git add" to track)
We’ve not yet saved anything or committed anything to git and therefore the ‘git status’ command reports that we are still in our initial commit. But now git sees a new file README.md in the repository which it does not know about and therefore refers to it under the category of untracked files.
The staging area
Before a file is committed or between two subsequent commits, files are placed in a staging area. We put the files that we need to be committed in the staging area and we do this by adding the files to the staging area. Once the files have been added to the staging area we can commit them.
Adding a file to the staging area:
To add a file to the staging area we use the git add command. Let’s add our README.md file to the staging area and then run the git status command again.
[sahil@linuxnix my_first_repo]$ git add README.md [sahil@linuxnix my_first_repo]$ [sahil@linuxnix my_first_repo]$ git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: README.md # [sahil@linuxnix my_first_repo]$
Notice that our file README.md is no longer an untracked file. Our file is now in the staging area and is ready to be committed.
Saving or committing the file to git
Now that our file has been successfully placed in the staging area we can commit it to git and track it. To commit the file we use the git commit command.
[sahil@linuxnix my_first_repo]$ git commit Added my first file # Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: README.md # ~ ~
Notice that running the git commit command opens the text editor that we specified in the core.editor parameter along with some pre-populated content. I had specified the core.editor as vim. Here we can add a description of the changes that were made in this commit. It is very important to write a message for every commit that you make so as to describe the changes made as part of the commit. Once we save our message and exit out of the editor, we see the below message:
[sahil@linuxnix my_first_repo]$ git commit [master (root-commit) f7eccb7] Added my first file 1 file changed, 1 insertion(+) create mode 100644 README.md [sahil@linuxnix my_first_repo]$
The above message means that I changed one file i.e. the README.md file and I added one line to the file as the new file contained only the one line.
Now with our first commit made let’s run the git status command again.
[sahil@linuxnix my_first_repo]$ git status # On branch master nothing to commit, working directory clean [sahil@linuxnix my_first_repo]$
Notice that now we do not get the message ‘Initial commit’ as part of the output. This is because we’ve made our first commit in this repository. The statement ‘nothing to commit, working directory clean’ means that there are no changes pending to be committed and everything that has been committed thus far is being tracked by git.
Conclusion
In this article, we explained the steps involved in adding new content to a freshly initialized git repository and we also defined some of the terms that are commonly used while working with git. In our next article, we will demonstrate how to update existing content in a git repository and we will also explain how to make use of the ‘git log’ command.
Sahil Suri
Latest posts by Sahil Suri (see all)
- Google Cloud basics: Activate Cloud Shell - May 19, 2021
- Create persistent swap partition on Azure Linux VM - May 18, 2021
- DNF, YUM and RPM package manager comparison - May 17, 2021
- Introduction to the aptitude package manager for Ubuntu - March 26, 2021
- zypper package management tool examples for managing packages on SUSE Linux - March 26, 2021

