
Its long time back I have learnt Heartbeat clustering around March-2008, but still this point I never implemented for production servers. This is my first attempt to do it and I am successful in implementing it for two node fail-over Cluster. Clustering is very complex and very advanced topic which I cannot deal with in one post. In this post I will give you some basics of Clustering, advantages of Clustering and configuration of simple fail-over Cluster.
Let’s start.
What is a Cluster any way?
Ans : A computer cluster is a group of linked computers, working together closely so that in many respects they form a single computer. The components of a cluster are commonly, but not always, connected to each other through fast local area networks. Clusters are usually deployed to improve performance and/or availability over that of a single computer, while typically being much more cost-effective than single computers of comparable speed or availability – www.wikipedia.org.
Cluster terminology.
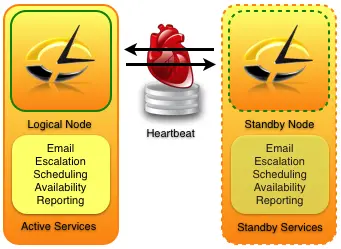
Node : It’s one of the system/computer which participates with other systems to form a Cluster.
Heartbeat : This a pulse kind of single which is send from all the nodes at regular intervals using a UDP packet so that each system will come to know the status of availability of other node. It’s a kind of door knocking activity like pinging a system, So that each node which are participating in Cluster will come to know the status of other nodes availability in the Cluster.
Floating IP or Virtual IP : This is the IP assigned to the Cluster through which user can access the services. So when ever clients request a service they will be arrived to this IP, and client will not know what are the back-end/actual ip addresses of the nodes. This virtual IP is used to nullify the effect of nodes going down.
Master node : This is the node most of the time where services are run in a High availability Cluster.
Slave node : This is the node which is used in High availability Cluster when master node is down. It will take over the role of servicing the users, when it will not receive heartbeat pulse from master. And automatically gives back the control when the master server is up and running. This slave comes to know about the status of master through heartbeat pulse/signals.
Types of Clusters:
Cluster types can be divided in to two main types
1. High availability :
These types of Clusters are configured where there should be no downtime. If one node in the cluster goes down second node will take care of serving users without interrupted service with availability of five nines i.e. 99.999%.
2. Load balancing :
These types of Clusters are configured where there are high loads from users. Advantages of load balancing are that users will not get any delays in their request because load on a single system is shared by two or more nodes in the Cluster.
Advantages of Cluster :
1.Reduced Cost : Its cheaper to by 10 normal servers and do cluster on them then buying a high end servers like blade servers, which will do more work than a single blade server which have more processing power.
2. Processing Power
3. Scalability
4. Availability
Configuration files details :
Three main configuration files :
· /etc/ha.d/authkeys
· /etc/ha.d/ha.cf
· /etc/ha.d/haresources
Some other configuration files/folders to know :
/etc/ha.d/resource.d. Files in this directory are very important which contains scripts to start/stop/restart a service run by this Heartbeat cluster.
Before configuration of Heartbeat Cluster these below points to be noted.
Note1 : The contents of ha.cf file are same in all the nodes in a cluster, except ucast and bcast derivatives.
Note2 : The contents of authkeys and haresources files are exact replica on all the nodes in a cluster.
Note3 : A cluster is used to provided a service with high availability/high performance, that service may be a web server, reverse proxy or a Database.
Test scenario setup:
1. The cluster configuration which I am going to show is a two node cluster with failover capability for a Squid reverse proxy..
2.For Squid reverse proxy configuration please click here..
3. Node details are as follows
Node1 :
IpAddress(eth0):10.77.225.21
Subnetmask(eth0):255.0.0.0
Default Gateway(eth0):10.0.0.1
IpAddress(eth1):192.168.0.1(To send heartbeat signals to other nodes)
Sub net mask (eth1):255.255.255.0
Default Gateway (eth1):None(don’t specify any thing, leave blank for this interface default gateway).
Node2 :
IpAddress(eth0):10.77.225.22
Subnetmask(eth0):255.0.0.0
Default Gateway (eth0):10.0.0.1
IpAddress(eth1):192.168.0.2(To send heartbeat signals to other nodes)
Sub net mask (eth1):255.255.255.0
Default Gateway(eth1):None(don’t specify any thing, leave blank for this interface default gateway).
tyle=”font-family: verdana;”>4. Floating Ip address:10.77.225.20
Lets start configuration of Heartbeat cluster. And make a note that ever step in this Heartbeat cluster configuration is divided in two parts parts
1.(configurations on node1)
2.(configurations on node2)
For better understanding purpose
Step1 : Install the following packages in the same order which is shown. If you did not find the packages online you can download it from our site, click here to download the packages.
Step1(a) : Install the following packages on node1
#rpm -ivh heartbeat-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-ldirectord-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-pils-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-stonith-2.1.2-2.i386.rpm
Step1(b) : Install the following packages on node2
#rpm -ivh heartbeat-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-ldirectord-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-pils-2.1.2-2.i386.rpm
#rpm -ivh heartbeat-stonith-2.1.2-2.i386.rpm
Step2 : By default the main configuration files (ha.cf, haresources and authkeys) are not present in /etc/ha.d/ folder we have to copy these three files from /usr/share/doc/heartbeat-2.1.2 to /etc/ha.d/
Step2(a) : Copy main configuration files from /usr/share/doc/heartbeat-2.1.2 to /etc/ha.d/ on node 1
#cp /usr/share/doc/heartbeat-2.1.2/ha.cf /etc/ha.d/
#cp /usr/share/doc/heartbeat-2.1.2/haresources /etc/ha.d/
#cp /usr/share/doc/heartbeat-2.1.2/authkeys /etc/ha.d/
Step2(b) : Copy main configuration files from /usr/share/doc/heartbeat-2.1.2 to /etc/ha.d/ on node 2
#cp /usr/share/doc/heartbeat-2.1.2/ha.cf /etc/ha.d/
#cp /usr/share/doc/heartbeat-2.1.2/haresources /etc/ha.d/
#cp /usr/share/doc/heartbeat-2.1.2/authkeys /etc/ha.d/
Step3 : Edit ha.cf file
#vi /etc/ha.d/ha.cf
Step3(a) : Edit ha.cf file as follows on node1
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 25
warntime 10
initdead 50
udpport 694
bcast eth1
ucast eth1 192.168.0.1
auto_failback on
node rp1.linuxnix.com
node rp2.linuxnix.com
Step3(b) : Edit ha.cf file as follows on node2
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 25
warntime 10
initdead 50
udpport 694
bcast eth1
ucast eth1 192.168.0.2
auto_failback on
node rp1.linuxnix.com
node rp2.linuxnix.com
Let me explain each entry in detail:
Debugfile : This is the file where debug info with good details for your heartbeat cluster will be stored, which is very much useful to do any kind of troubleshooting.
Logfile : This is the file where general logging of heartbeat cluster takes place.
Logfacility : This directive is used to specify where to log your heartbeat logs(if it’s local that indicates store logs locally or if it’s a syslog then store it on remote server and none to disable logging). And there are so many other options, please explore yourself.
Keepalive : This directive is used to set the time interval between heartbeat packets and the nodes to check the availability of other nodes. In this example I specified it as two seconds(keepalive 2).
Deadtime : A node is said to be dead if the other node didn’t receive any update form it.
Warntime : Time in seconds before issuing a “late heartbeat” warning in the logs.
Initdead : With some configurations, the network takes some time to start working after a reboot. This is a separate “deadtime” to handle that case. It should be at least twice the normal deadtime.
Udpport : This is the port used by heartbeat to send heartbeat packet/signals to other nodes to check availability(here in this example I used default port:694).
Bcast : Used to specify on which device/interface to broadcast the heartbeat packets.
Ucast : Used to specify on which device/interface to uni-cast the heartbeat packets.
auto_failback : This option determines whether a resource will automatically fail back to it’s “primary” node, or remain on whatever node is serving it until that node fails, or an administrator intervenes. In my example I have given as on that indicate if the failed node come back online, control will be given to this node automatically. Let me put it in this way. I have two nodes node1 and node2. My node one machine is a high end one and node is for serving temporary purpose when node 1 goes down. Suppose node1 goes down, node2 will take the control and serve the service, and it will check periodically for node1 starts once it find that node 1 is up, the control is given to node1.
Node : This is used to specify the participated nodes in the cluster. In my cluster only two nodes are participating (rp1 and rp2) so just specify that entries. If in your implementation more nodes are participating please specify a
ll the nodes.
Step4 : Edit haresources file
#vi /etc/ha.d/haresources
Step4(a) : Just specify below entry in last line of this file on node1
rp1.linuxnix.com 10.77.225.20 squid
Step4(b) : Just specify below entry in last line of this file on node1
rp1.linuxnix.com 10.77.225.20 squid
Explanation of each entry :
rp1.linuxnix.com is the main node in the cluster
10.77.225.20 is the floating ip address of this cluster.
Squid : This is the service offered by the cluster. And make a note that this is the script file located in /etc/ha.d/ resource.d/.
Note : By default squid script file will not be there in that folder, I created it according to my squid configuration.
What actually this script file contains?
Ans : This is just a start/stop/restart script for the particular service. So that heartbeat cluster will take care of the starting/stoping/restarting of the service(here it’s squid).
Here is what squid script file contains.
http://sites.google.com/site/surendra/Home/squid.txt.txt?attredirects=0&d;=1
Step5 : Edit authkeys file, he authkeys configuration file contains information for Heartbeat to use when authenticating cluster members. It cannot be readable or writeable by anyone other than root. so change the permissions of the file to 600 on both the nodes..
Two lines are required in the authkeys file:
A line which says which key to use in signing outgoing packets.
One or more lines defining how incoming packets might be being signed.
Step5 (a) : Edit authkeys file on node1
#vi /etc/ha.d/authkeys
auth 2
#1 crc
2 sha1 HI!
#3 md5 Hello!
Now save and exit the file
Step5 (b) : Edit authkeys file on node2
#vi /etc/ha.d/authkeys
auth 2
#1 crc
2 sha1 HI!
#3 md5 Hello!
Now save and exit the file
Step6 : Edit /etc/hosts file to give entries of host-names for the nodes
Step6(a) : Edit /etc/hosts file on node1 as below
Step6(b) : Edit /etc/hosts file on node2 as below
10.77.225.22 rp2.linuxnix.com rp2
Step7 : Start Heartbeat cluster
Step7(a) : Start heartbeat cluster on node1
#service heartbeat start
Step7(b) : Start heartbeat cluster on node2
#service heartbeat start
Checking your Heartbeat cluster:
If your heartbeat cluster is running fine a Virtual Ethernet Interface is created on node1 and 10.77.225.20
Clipped output of my first node
# ifconfig
Eth0 Link encap:Ethernet HWaddr 00:02:A5:4C:AF:8E
inet addr:10.77.225.21 Bcast:10.77.231.255 Mask:255.255.248.0
inet6 addr: fe80::202:a5ff:fe4c:af8e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5714248 errors:0 dropped:0 overruns:0 frame:0
TX packets:19796 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1533278899 (1.4 GiB) TX bytes:4275200 (4.0 MiB)
Base address:0x5000 Memory:f7fe0000-f8000000
Eth0:0 Link encap:Ethernet HWaddr 00:02:A5:4C:AF:8E
inet addr:10.77.225.20 Bcast:10.77.231.255 Mask:255.255.248.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Base address:0x5000 Memory:f7fe0000-f8000000
Eth1 Link encap:Ethernet HWaddr 00:02:A5:4C:AF:8F
inet addr:192.168.0.1 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::202:a5ff:fe4c:af8f/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:145979 errors:0 dropped:0 overruns:0 frame:0
TX packets:103753 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:38966724 (37.1 MiB) TX bytes:27640765 (26.3 MiB)
Base address:0x5040 Memory:f7f60000-f7f80000
Try accessing your browser whether Squid is working fine or not. Please follow up coming posts how to troubleshoot heartbeat cluster.
Latest posts by Surendra Anne (see all)
- Docker: How to copy files to/from docker container - June 30, 2020
- Anisble: ERROR! unexpected parameter type in action:
Fix - June 29, 2020 - FREE: JOIN OUR DEVOPS TELEGRAM GROUPS - August 2, 2019
- Review: Whizlabs Practice Tests for AWS Certified Solutions Architect Professional (CSAP) - August 27, 2018
- How to use ohai/chef-shell to get node attributes - July 19, 2018

